Automating blender based hillshading with Python
Remember my Blend based hillshading? I promised to try to automate it, right? Well, it seems I have the interest and stamina now, so that's what I'm doing. But boys and girls and anything in between and beyond, the stamina is waning and the culprit is Blender's internals being exposed into a non-Pythonic API3. I swear if I worked in anything remotely close to this, I would be writing a wrapper for all this. But in the meantime, it's all a discovery path to something that does not resemble a hack. Just read some of Blender's Python Quickstart:
When you are familiar with other Python APIs you may be surprised that new data-blocks in the bpy API cannot be created by calling the class:
bpy.types.Mesh() Traceback (most recent call last): File "<blender_console>", line 1, in <module> TypeError: bpy_struct.__new__(type): expected a single argument
This is an intentional part of the API design. The Blender Python API can’t create Blender data that exists outside the main Blender database (accessed through bpy.data), because this data is managed by Blender (save, load, undo, append, etc).
Data is added and removed via methods on the collections in bpy.data, e.g:
mesh = bpy.data.meshes.new(name="MyMesh")
That is, instead of making the constructor call this internal API, they make it fail miserably and force you to use the internal API! Today I was mentioning that Asterisk's programming language was definitely designed by a Telecommunications Engineer, so I guess this one was designed by a 3D artist? But I digress...
One of the first thing about Blender's internals is that one way to work is based on Contexts. This makes sense when developing plugins, where you mostly need to apply things to the selected object, but for someone really building everything from scratch like I need to, it feels weird.
One of the advantages is that you can open a Python console and let Blender show you the calls it makes for every step you make on the UI, but it's so context based that the results is useless as a script. Or for instance, linking the output of a thing into he the input of another is registered as a drag-and-drop call that includes the distance the mouse moved during the drag, so it's relative of the output dot where you started and what it links to also depends on the physical and not logical position of the things you're linking,
bpy.ops.node.link(detach=False, drag_start=(583.898, 257.74))
It takes quite a lot of digging around in a not very friendly REPL1 with limited scrollback and not much documentation to find more reproducible, less context dependent alternatives. This is what's eating up my stamina, it's not so fun anymore. Paraphrasing someone on Mastodon: What use is a nice piece of Open Software if it's documentation is not enough to be useful2?
Another very important thing is that all objects have two views: one that has generic properties like position and
rotation, which can be reacheched by bpy.data.objects; and one that has specific properties like a light's power or a
camera's lens angle, which can be reached by f.i. bpy.data.cameras. This was utterly confusing, specially since
all bpy.data's documentation is 4 lines long. Later I found out you can get specific data from the generic one in
the .data attribute, so the take out is: always get your objects from bpy.data.objects.
Once we get over that issue, things are quite straightforward, but not necessarily easy. The script as it is can already
be used with blender --background --python <script_file>, but have in account that when you do that, you start with
the default generic 3D setup, with a light, a camera and a cube. You have to delete the cube, but you can get a
reference to the other two to reuse them.
Then comes the administrative stuff around just rendering the scene. To industrialize it and be able to quickly test
stuff, you can try to get command line options. You can use Python's argparser module for this, but have in account
that those --background --python blender.py options are going to be passed to the script, so you either ignore unknown
options or you declare those too:
mdione@ioniq:~/src/projects/elevation$ blender --background --python blender.py Blender 3.6.2 Read prefs: "/home/mdione/.config/blender/3.6/config/userpref.blend" usage: blender [-h] [--render-samples RENDER_SAMPLES] [--render-scale RENDER_SCALE] [--height-scale HEIGHT_SCALE] FILE blender: error: unrecognized arguments: --background --python
Also, those options are going to be passed to Blender! So at the end of your run, Blender is going to complain that it doesn't understand your options:
unknown argument, loading as file: --render-samples Error: Cannot read file "/home/mdione/src/projects/elevation/--render-samples": No such file or directory Blender quit
The other step you should do is to copy the Geo part of GeoTIFF to the output file. I used rasterio, mostly because at
first I tried gdal (I was already using gdal_edit.py to do this in my previous manual procedure), but it's API was
quite confusing and rasterio's is more plain. But, rasterio can't actually open a file just to write the metadata
like gdal does, so I had to open the output file, read all data, open it again for writing (this truncates the file)
and write metadata and data.
Now, some caveats. First, as I advanced in my last post, the method as it is right now has issues at the seams. Blender can't read GDAL VRT files, so either I build 9 planes instead of 1 (all the neighbors are needed to properly calculate the shadows because Blender is also taking in account light reflected back from other features, meaning mountains) or for each 1x1 tile I generate another with some buffer. I will try the first one and see if it fixes this issue without much runtime impact.
Second, the script is not 100% parametrized. Sun size and power are fixed based on my tests. Maybe in the future. Third, I will try to add a scattering sky, so we get a bluish tint to the shadows, and set the Sun's color to something yellowish. These should probably be options too.
Fourth, and probably most important. I discovered that this hillshading method is really sensible to missing or bad data, because they look like dark, deep holes. This is probably a deal breaker for many, so you either fix your data, or you search for better data, or you live with it. I'm not sure what I'm going to do.
So, what did I do with this? Well, first, find good parameters, one for render samples and another for height scale. Render time grows mostly linearly with render samples, so I just searched for the one before detail stopped appearing; the value I found was 120 samples. When we left off I was using 10 instead of 5 for height scale, but it looks too exaggerated on hills (but it looks AWESOME in mountains like the Mount Blanc/Monte Bianco! See below), so I tried to pinpoint a good balance. For me it's 8, maybe 7.
Why get these values right? Because like I mentioned before, a single 1x1°, 3601x5137px tile takes some 40m in my laptop
at 100 samples, so the more tuned the better. One nice way to quickly test is to lower the samples or use the
--render-scale option of the script to reduce the size of the output. Note that because you reduce both dimensions at
the same time, the final render (and the time that takes) is actually the square of this factor: 50% is actually 25%
(because 0.50 * 0.50 = 0.25).
So, without further addo, here's my script. If you find it useful but want more power, open issues or PRs, everything is welcome.
https://github.com/StyXman/blender_hilllshading 5
Try to use the main branch; develop is considered unstable and can be broken.
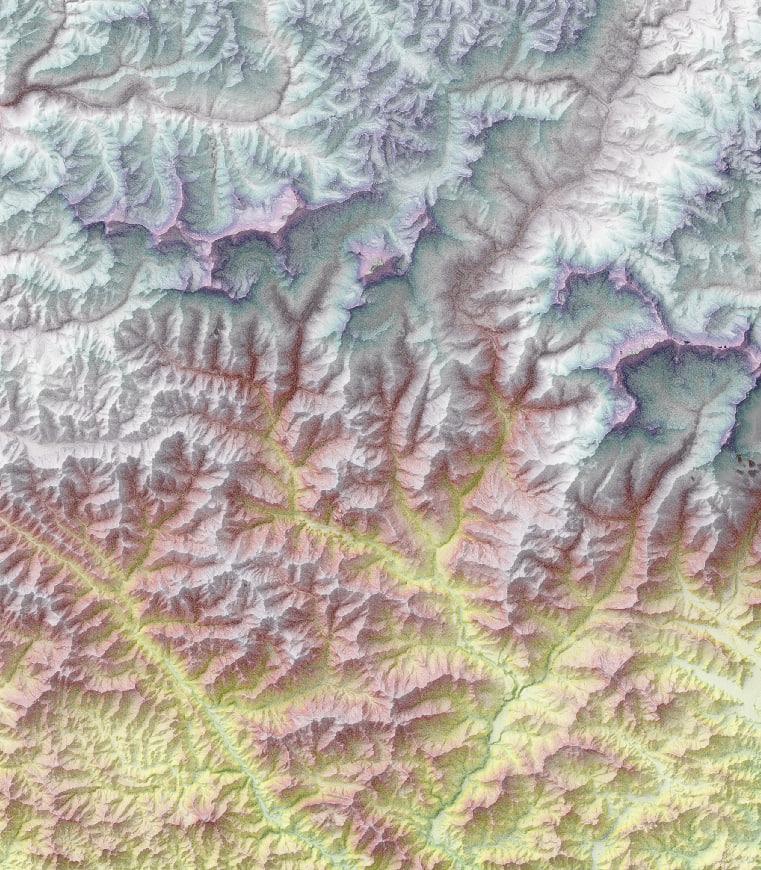
A couple of images of the shadows applied to my style as teaser, both using only 20 samples and x10 height scale:
Dhaulagiri:
Mont Blanc/Monte Bianco:
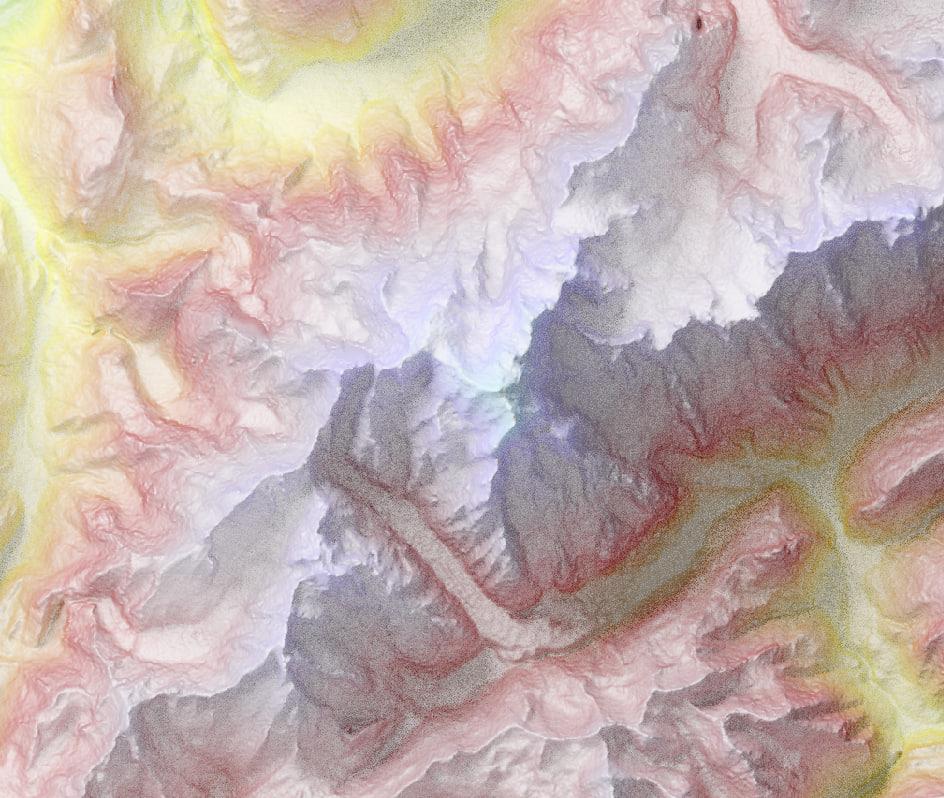
Man, I love the fact that the tail of the Giacchiaio del Miage is in shadows, but the rest is not; or how Monte Bianco/Mont Blanc's shadow reaches across the valley to the base of la Tête d'Arp. But also notice the bad data close to la Mer de Glace.
-
Ok, TBH here, I'm very much used to
ipython's console, it's really closer to the plainpythonone. No tab completion, so lots of calls todir()and a fewhelp()s. ↩ -
I couldn't find it again. Mastodon posts are not searchable by default, which I understand is good for privacy, but on the other hand the current clients don't store anything locally, so you can't even search what you already saw. I have several semi-ranting posts about this and I would show them to you, but they got lost on Mastodon. See what I mean? ↩
-
So you have an idea, this took me a whole week of free time to finish, including but not in the text, my old nemesis, terracing effect. This thing is brittle. ↩
-
Yeah, maybe the API is mostly designed for this. ↩
-
My site generator keeps breaking. This is the second time I have to publicly admit this. Maybe next weekend I'll gather steam and replace it with
nikola. ↩