Disk usage while importing an OSM rendering database
Preface: I wanted to include the updating part in this post, but it got too long already, so I'll split it in two. I will update this post when the second comes out.
TL;DR version: import seems to use a peak of 15x space compared to the .osm.pbf source file, and a final 10x. If
you're tight on space, try --number-processes 1, but it will be way slower. You can also save some 4x size if you have
4x RAM (by not using --flat-nodes).
I decided to try and maintain a daily OpenStreetMap rendering database for Europe. The plan is to, at some point, have a rendering server at home, instead of depending of occasional renderings. For this I will use my old laptop, which has a 1TB SSD and only 8GiB of RAM, which I plan to upgrade to 16 at some point. The machines does a few other things (webmail, backups, cloud with only two users, and other stuff), but the usage is really low, so I think it'll be fine.
This week I cleaned up disk space and I prepared the main import. Due to the space constraints I wanted to know how the disk usage evolves during the import. In particular, I wanted to see if there could be a index creation order which could be beneficial for people with limited space for these operations. Let's check the times first2:
$ osm2pgsql --verbose --database gis --cache 0 --number-processes 4 --slim --flat-nodes $(pwd)/nodes.cache --hstore --multi-geometry \ --style $osm_carto/openstreetmap-carto.style --tag-transform-script $osm_carto/openstreetmap-carto.lua europe-latest.osm.pbf 2023-08-18 15:46:20 osm2pgsql version 1.8.0 2023-08-18 15:46:20 [0] Database version: 15.3 (Debian 15.3-0+deb12u1) 2023-08-18 15:46:20 [0] PostGIS version: 3.3 2023-08-18 15:46:20 [0] Setting up table 'planet_osm_nodes' 2023-08-18 15:46:20 [0] Setting up table 'planet_osm_ways' 2023-08-18 15:46:20 [0] Setting up table 'planet_osm_rels' 2023-08-18 15:46:20 [0] Setting up table 'planet_osm_point' 2023-08-18 15:46:20 [0] Setting up table 'planet_osm_line' 2023-08-18 15:46:20 [0] Setting up table 'planet_osm_polygon' 2023-08-18 15:46:20 [0] Setting up table 'planet_osm_roads' 2023-08-19 20:49:52 [0] Reading input files done in 104612s (29h 3m 32s). 2023-08-19 20:49:52 [0] Processed 3212638859 nodes in 3676s (1h 1m 16s) - 874k/s 2023-08-19 20:49:52 [0] Processed 390010251 ways in 70030s (19h 27m 10s) - 6k/s 2023-08-19 20:49:52 [0] Processed 6848902 relations in 30906s (8h 35m 6s) - 222/s 2023-08-19 20:49:52 [0] Overall memory usage: peak=85815MByte current=85654MByte
Now I wonder why I have --cache 0. Unluckily I didn't leave any comments, so I'll have to check my commits (I automated
all this with a script :). Unluckily again, this slipped in in a commit about something else, so any references are
lost :( Here are the table sizes1:
Name | Type | Access method | Size --------------------+-------+---------------+---------------- planet_osm_ways | table | heap | 95_899_467_776 planet_osm_polygon | table | heap | 92_916_039_680 * planet_osm_line | table | heap | 43_485_192_192 * planet_osm_point | table | heap | 16_451_903_488 * planet_osm_roads | table | heap | 6_196_699_136 * planet_osm_rels | table | heap | 3_488_505_856 spatial_ref_sys | table | heap | 7_102_464 geography_columns | view | | 0 geometry_columns | view | | 0
Those marked with * are used for rendering, the rest are kept for update purposes. Let's see the disk usage [click to
get the full image]:
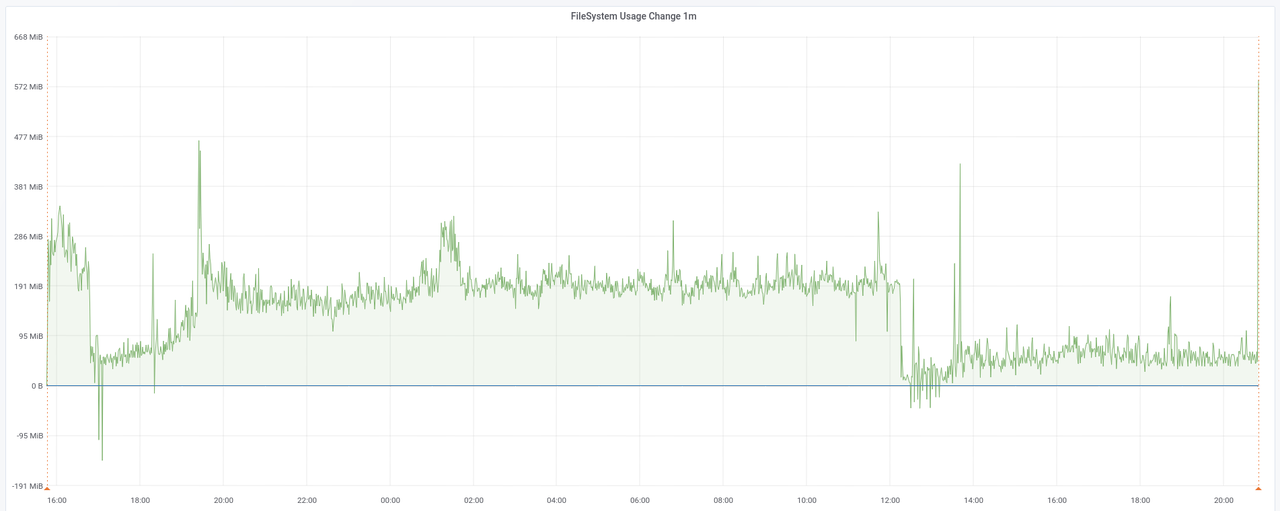
The graph shows the rate at which disk is used during the import of data. We can only see some space being freed around 1/10th in, and later at around 2/3rds, but nothing major.
Then osm2pgsql does a lot of stuff, including clustering, indexing and analyzing:
2023-08-19 20:49:52 [1] Clustering table 'planet_osm_polygon' by geometry... 2023-08-19 20:49:52 [2] Clustering table 'planet_osm_line' by geometry... 2023-08-19 20:49:52 [3] Clustering table 'planet_osm_roads' by geometry... 2023-08-19 20:49:52 [4] Clustering table 'planet_osm_point' by geometry... 2023-08-19 20:49:52 [1] Using native order for clustering table 'planet_osm_polygon' 2023-08-19 20:49:52 [2] Using native order for clustering table 'planet_osm_line' 2023-08-19 20:49:52 [3] Using native order for clustering table 'planet_osm_roads' 2023-08-19 20:49:52 [4] Using native order for clustering table 'planet_osm_point' 2023-08-19 22:35:50 [3] Creating geometry index on table 'planet_osm_roads'... 2023-08-19 22:50:47 [3] Creating osm_id index on table 'planet_osm_roads'... 2023-08-19 22:55:52 [3] Analyzing table 'planet_osm_roads'... 2023-08-19 22:57:47 [3] Done task [Analyzing table 'planet_osm_roads'] in 7674389ms. 2023-08-19 22:57:47 [3] Starting task... 2023-08-19 22:57:47 [3] Done task in 1ms. 2023-08-19 22:57:47 [3] Starting task... 2023-08-19 22:57:47 [0] Done postprocessing on table 'planet_osm_nodes' in 0s 2023-08-19 22:57:47 [3] Building index on table 'planet_osm_ways' 2023-08-19 23:32:06 [4] Creating geometry index on table 'planet_osm_point'... 2023-08-20 00:13:30 [4] Creating osm_id index on table 'planet_osm_point'... 2023-08-20 00:20:35 [4] Analyzing table 'planet_osm_point'... 2023-08-20 00:20:40 [4] Done task in 12647156ms. 2023-08-20 00:20:40 [4] Starting task... 2023-08-20 00:20:40 [4] Building index on table 'planet_osm_rels' 2023-08-20 02:03:11 [4] Done task in 6151838ms. 2023-08-20 03:17:24 [2] Creating geometry index on table 'planet_osm_line'... 2023-08-20 03:54:40 [2] Creating osm_id index on table 'planet_osm_line'... 2023-08-20 04:02:57 [2] Analyzing table 'planet_osm_line'... 2023-08-20 04:03:01 [2] Done task in 25988218ms. 2023-08-20 05:26:21 [1] Creating geometry index on table 'planet_osm_polygon'... 2023-08-20 06:17:31 [1] Creating osm_id index on table 'planet_osm_polygon'... 2023-08-20 06:30:46 [1] Analyzing table 'planet_osm_polygon'... 2023-08-20 06:30:47 [1] Done task in 34854542ms. 2023-08-20 10:48:18 [3] Done task in 42630605ms. 2023-08-20 10:48:18 [0] Done postprocessing on table 'planet_osm_ways' in 42630s (11h 50m 30s) 2023-08-20 10:48:18 [0] Done postprocessing on table 'planet_osm_rels' in 6151s (1h 42m 31s) 2023-08-20 10:48:18 [0] All postprocessing on table 'planet_osm_point' done in 12647s (3h 30m 47s). 2023-08-20 10:48:18 [0] All postprocessing on table 'planet_osm_line' done in 25988s (7h 13m 8s). 2023-08-20 10:48:18 [0] All postprocessing on table 'planet_osm_polygon' done in 34854s (9h 40m 54s). 2023-08-20 10:48:18 [0] All postprocessing on table 'planet_osm_roads' done in 7674s (2h 7m 54s). 2023-08-20 10:48:18 [0] Overall memory usage: peak=85815MByte current=727MByte 2023-08-20 10:48:18 [0] osm2pgsql took 154917s (43h 1m 57s) overall.
I tried to make sense of this part. We have 4 workers 1-4 plus one main thread 0. On the 19th, ~20:50, all four workers
start working on polygon, line, roads and point respectively. 2h07m54s later worker 3 finishes clustering
roads, which is the time reported at the end of the run. But immediately starts creating indexes for it, which take ~15m and
~5m each. It then starts analyzing roads, which I guess it's the task that finishes at 22:57 (~2m runtime)?
Then 2 anonymous tasks, one finishes in 1ms, and the second lingers...? And immediately starts indexing ways.
Meanwhile, nodes, which wasn't reported as being processed by any worker, also finishes. Maybe it's the main loop
which does it? And if so, why did it finish only now, after only 0s? All this happens on the same second, 10:48:18.
Still on the 19th, at ~23:32, worker 4 starts creating indexes for point. This is ~3h30m after it started
clustering it, which is also what is reported at the end. Again, 2 indexes and one analysis for this table, then an
anonymous task... which I guess finishes immediately? Because on the same second it creates an index for it, which looks
like a pattern (W3 did the same, remember?). It finishes in ~1h40m, so I guess W3's "Done task" at the end is the index
it was creating since the 19th?
Given all that, I added some extra annotations that I think are the right ones to make sense of all that. I hope I can use some of my plenty spare time to fix it, see this issue:
2023-08-19 20:49:52 [1] Clustering table 'planet_osm_polygon' by geometry... 2023-08-19 20:49:52 [2] Clustering table 'planet_osm_line' by geometry... 2023-08-19 20:49:52 [3] Clustering table 'planet_osm_roads' by geometry... 2023-08-19 20:49:52 [4] Clustering table 'planet_osm_point' by geometry... 2023-08-19 20:49:52 [1] Using native order for clustering table 'planet_osm_polygon' 2023-08-19 20:49:52 [2] Using native order for clustering table 'planet_osm_line' 2023-08-19 20:49:52 [3] Using native order for clustering table 'planet_osm_roads' 2023-08-19 20:49:52 [4] Using native order for clustering table 'planet_osm_point' 2023-08-19 22:35:50 [3] Creating geometry index on table 'planet_osm_roads'... 2023-08-19 22:50:47 [3] Creating osm_id index on table 'planet_osm_roads'... 2023-08-19 22:55:52 [3] Analyzing table 'planet_osm_roads'... 2023-08-19 22:57:47 [3] Done task [Analyzing table 'planet_osm_roads'] in 7674389ms. 2023-08-19 22:57:47 [3] Starting task [which one?]... 2023-08-19 22:57:47 [3] Done task in 1ms. 2023-08-19 22:57:47 [3] Starting task [which one?]... 2023-08-19 22:57:47 [0] Done postprocessing on table 'planet_osm_nodes' in 0s 2023-08-19 22:57:47 [3] Building index on table 'planet_osm_ways' 2023-08-19 23:32:06 [4] Creating geometry index on table 'planet_osm_point'... 2023-08-20 00:13:30 [4] Creating osm_id index on table 'planet_osm_point'... 2023-08-20 00:20:35 [4] Analyzing table 'planet_osm_point'... 2023-08-20 00:20:40 [4] Done task [Analyzing table 'planet_osm_point'] in 12647156ms. 2023-08-20 00:20:40 [4] Starting task... 2023-08-20 00:20:40 [4] Building index on table 'planet_osm_rels' 2023-08-20 02:03:11 [4] Done task [Building index on table 'planet_osm_rels'] in 6151838ms. 2023-08-20 03:17:24 [2] Creating geometry index on table 'planet_osm_line'... 2023-08-20 03:54:40 [2] Creating osm_id index on table 'planet_osm_line'... 2023-08-20 04:02:57 [2] Analyzing table 'planet_osm_line'... 2023-08-20 04:03:01 [2] Done task [Analyzing table 'planet_osm_line'] in 25988218ms. 2023-08-20 05:26:21 [1] Creating geometry index on table 'planet_osm_polygon'... 2023-08-20 06:17:31 [1] Creating osm_id index on table 'planet_osm_polygon'... 2023-08-20 06:30:46 [1] Analyzing table 'planet_osm_polygon'... 2023-08-20 06:30:47 [1] Done task [Analyzing table 'planet_osm_polygon'] in 34854542ms. 2023-08-20 10:48:18 [3] Done task [Building index on table 'planet_osm_ways'] in 42630605ms. 2023-08-20 10:48:18 [0] Done postprocessing on table 'planet_osm_ways' in 42630s (11h 50m 30s) 2023-08-20 10:48:18 [0] Done postprocessing on table 'planet_osm_rels' in 6151s (1h 42m 31s) 2023-08-20 10:48:18 [0] All postprocessing on table 'planet_osm_point' done in 12647s (3h 30m 47s). 2023-08-20 10:48:18 [0] All postprocessing on table 'planet_osm_line' done in 25988s (7h 13m 8s). 2023-08-20 10:48:18 [0] All postprocessing on table 'planet_osm_polygon' done in 34854s (9h 40m 54s). 2023-08-20 10:48:18 [0] All postprocessing on table 'planet_osm_roads' done in 7674s (2h 7m 54s). 2023-08-20 10:48:18 [0] Overall memory usage: peak=85815MByte current=727MByte 2023-08-20 10:48:18 [0] osm2pgsql took 154917s (43h 1m 57s) overall.
Here's the graph for that section [click to enlarge]:
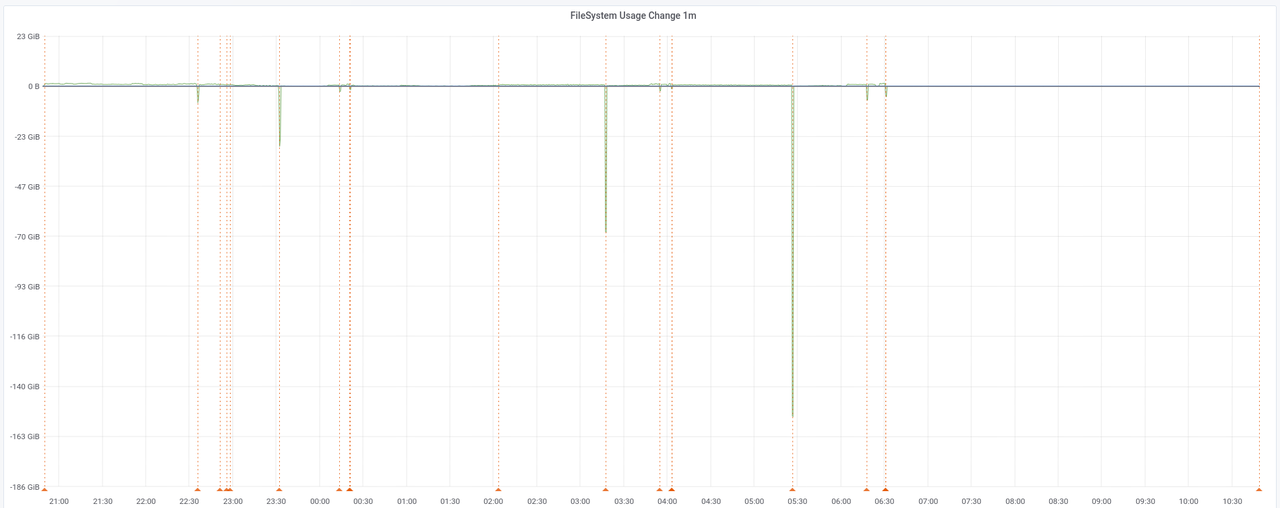
If you look closer, you can barely see the indexes being created, but the most popping up features are the peaks of space being freed. These correspond to points were some task has just finished and another one begins. Correlating back with those logs, and taking just the 4 bigger ones, we get (in chronological order):
- Clustering the
roadstable frees 10GiB. - Clustering the
pointtable frees 24GiB. - Clustering the
linetable frees 68GiB. - Clustering the
polygontable frees 153GiB.
Which makes a lot of sense. But there's nothing for us here if we want to reorder stuff because they're all started in
parallel, and we could only reorder them if we set --number-processes 1. The space being freed more or less
corresponds (at least in terms of orders of magnitude) to the sizes of the final tables we see above. These are also the
main rendering tables. The rest is space freed when finishing creating indexes, but the amounts are so small that I'm
not going to focus on them. Also, notice that most of the space is freed after the last of those four events because the
original data is bigger and so it takes longer to process.
As a side note, I generated the above graphs using Prometheus, Grafana and its annotations. One of the good things about
Grafana is that it has an API that allows you to do a lot of stuff (but surprisingly, not list Dashboards, although I
guess I could use the search API for that). I tried to do it with Python and requests but for some reason it didn't
work3:
Update: the mistake was using requests.put() instead of requests.post(). Another consequence of writing for hours
until late at night.
I left finding out why for another time because I managed to do the annotations with curl:
$ python3 -c 'import datetime, sys; time = datetime.datetime.strptime(sys.argv[1], "%Y-%m-%d %H:%M:%S"); print(int(time.timestamp()) * 1000)' '2023-08-20 10:48:18' 1692521298000 $ curl --verbose --request POST --user 'admin:aing+ai3eiv7Aexu5Shi' http://diablo:3000/api/annotations --header 'Content-Type: application/json' \ --data '{ "dashboardId": 1, "panelId": 26, "time": 1692521298000, "text": "Done task [Building index on table planet_osm_ways]" }'
(Yes. All annotations. By hand. And double-checked the next day, because I was doing them until so late I made a few mistakes.)
Here are the indexes this step creates and their sizes:
Name | Table | Access method | Size ---------------------------------------------+-------------------------------------+---------------+---------------- planet_osm_ways_nodes_bucket_idx | planet_osm_ways | gin | 11_817_369_600 planet_osm_polygon_way_idx | planet_osm_polygon | gist | 11_807_260_672 planet_osm_ways_pkey | planet_osm_ways | btree | 8_760_164_352 planet_osm_polygon_osm_id_idx | planet_osm_polygon | btree | 6_186_663_936 planet_osm_point_way_idx | planet_osm_point | gist | 4_542_480_384 planet_osm_line_way_idx | planet_osm_line | gist | 4_391_354_368 planet_osm_line_osm_id_idx | planet_osm_line | btree | 2_460_491_776 planet_osm_point_osm_id_idx | planet_osm_point | btree | 2_460_352_512 planet_osm_rels_parts_idx | planet_osm_rels | gin | 2_093_768_704 planet_osm_roads_way_idx | planet_osm_roads | gist | 291_995_648 planet_osm_rels_pkey | planet_osm_rels | btree | 153_853_952 planet_osm_roads_osm_id_idx | planet_osm_roads | btree | 148_979_712 spatial_ref_sys_pkey | spatial_ref_sys | btree | 212_992
Even when the sizes are quite big (51GiB total), it's below the peak extra space (124GiB), so we can also ignore this.
Then it's time to create some indexes with an SQL file provided by osm-carto. psql does not print timestamps for the
lines, so I used my trusty pefan script to add them2:
$ time psql --dbname gis --echo-all --file ../../osm-carto/indexes.sql | pefan -t 2023-08-22T21:08:59.516386: -- These are indexes for rendering performance with OpenStreetMap Carto. 2023-08-22T21:08:59.516772: -- This file is generated with scripts/indexes.py 2023-08-22T21:08:59.516803: CREATE INDEX planet_osm_line_ferry ON planet_osm_line USING GIST (way) WHERE route = 'ferry' AND osm_id > 0; 2023-08-22T21:10:17.226963: CREATE INDEX 2023-08-22T21:10:17.227708: CREATE INDEX planet_osm_line_label ON planet_osm_line USING GIST (way) WHERE name IS NOT NULL OR ref IS NOT NULL; 2023-08-22T21:13:20.074513: CREATE INDEX 2023-08-22T21:13:20.074620: CREATE INDEX planet_osm_line_river ON planet_osm_line USING GIST (way) WHERE waterway = 'river'; 2023-08-22T21:14:41.430259: CREATE INDEX 2023-08-22T21:14:41.430431: CREATE INDEX planet_osm_line_waterway ON planet_osm_line USING GIST (way) WHERE waterway IN ('river', 'canal', 'stream', 'drain', 'ditch'); 2023-08-22T21:16:22.528526: CREATE INDEX 2023-08-22T21:16:22.528618: CREATE INDEX planet_osm_point_place ON planet_osm_point USING GIST (way) WHERE place IS NOT NULL AND name IS NOT NULL; 2023-08-22T21:17:05.195416: CREATE INDEX 2023-08-22T21:17:05.195502: CREATE INDEX planet_osm_polygon_admin ON planet_osm_polygon USING GIST (ST_PointOnSurface(way)) WHERE name IS NOT NULL AND boundary = 'administrative' AND admin_level IN ('0', '1', '2', '3', '4'); 2023-08-22T21:20:00.114673: CREATE INDEX 2023-08-22T21:20:00.114759: CREATE INDEX planet_osm_polygon_military ON planet_osm_polygon USING GIST (way) WHERE (landuse = 'military' OR military = 'danger_area') AND building IS NULL; 2023-08-22T21:22:53.872835: CREATE INDEX 2023-08-22T21:22:53.872917: CREATE INDEX planet_osm_polygon_name ON planet_osm_polygon USING GIST (ST_PointOnSurface(way)) WHERE name IS NOT NULL; 2023-08-22T21:26:36.166407: CREATE INDEX 2023-08-22T21:26:36.166498: CREATE INDEX planet_osm_polygon_name_z6 ON planet_osm_polygon USING GIST (ST_PointOnSurface(way)) WHERE name IS NOT NULL AND way_area > 5980000; 2023-08-22T21:30:00.829190: CREATE INDEX 2023-08-22T21:30:00.829320: CREATE INDEX planet_osm_polygon_nobuilding ON planet_osm_polygon USING GIST (way) WHERE building IS NULL; 2023-08-22T21:35:40.274071: CREATE INDEX 2023-08-22T21:35:40.274149: CREATE INDEX planet_osm_polygon_water ON planet_osm_polygon USING GIST (way) WHERE waterway IN ('dock', 'riverbank', 'canal') OR landuse IN ('reservoir', 'basin') OR "natural" IN ('water', 'glacier'); 2023-08-22T21:38:54.905074: CREATE INDEX 2023-08-22T21:38:54.905162: CREATE INDEX planet_osm_polygon_way_area_z10 ON planet_osm_polygon USING GIST (way) WHERE way_area > 23300; 2023-08-22T21:43:20.125524: CREATE INDEX 2023-08-22T21:43:20.125602: CREATE INDEX planet_osm_polygon_way_area_z6 ON planet_osm_polygon USING GIST (way) WHERE way_area > 5980000; 2023-08-22T21:47:05.219135: CREATE INDEX 2023-08-22T21:47:05.219707: CREATE INDEX planet_osm_roads_admin ON planet_osm_roads USING GIST (way) WHERE boundary = 'administrative'; 2023-08-22T21:47:27.862548: CREATE INDEX 2023-08-22T21:47:27.862655: CREATE INDEX planet_osm_roads_admin_low ON planet_osm_roads USING GIST (way) WHERE boundary = 'administrative' AND admin_level IN ('0', '1', '2', '3', '4'); 2023-08-22T21:47:30.879559: CREATE INDEX 2023-08-22T21:47:30.879767: CREATE INDEX planet_osm_roads_roads_ref ON planet_osm_roads USING GIST (way) WHERE highway IS NOT NULL AND ref IS NOT NULL; 2023-08-22T21:47:41.250887: CREATE INDEX real 38m41,802s user 0m0,098s sys 0m0,015s
The generated indexes and sizes:
Name | Table | Access method | Size ---------------------------------------------+-------------------------------------+---------------+---------------- planet_osm_polygon_nobuilding | planet_osm_polygon | gist | 2_314_887_168 planet_osm_line_label | planet_osm_line | gist | 1_143_644_160 planet_osm_polygon_way_area_z10 | planet_osm_polygon | gist | 738_336_768 planet_osm_line_waterway | planet_osm_line | gist | 396_263_424 planet_osm_polygon_name | planet_osm_polygon | gist | 259_416_064 planet_osm_polygon_water | planet_osm_polygon | gist | 188_227_584 planet_osm_roads_roads_ref | planet_osm_roads | gist | 147_103_744 planet_osm_point_place | planet_osm_point | gist | 138_854_400 planet_osm_roads_admin | planet_osm_roads | gist | 47_947_776 planet_osm_polygon_way_area_z6 | planet_osm_polygon | gist | 24_559_616 planet_osm_line_river | planet_osm_line | gist | 17_408_000 planet_osm_polygon_name_z6 | planet_osm_polygon | gist | 13_336_576 planet_osm_roads_admin_low | planet_osm_roads | gist | 2_424_832 planet_osm_polygon_military | planet_osm_polygon | gist | 925_696 planet_osm_line_ferry | planet_osm_line | gist | 425_984 planet_osm_polygon_admin | planet_osm_polygon | gist | 32_768
The sizes are small enough to ignore.
The last step is to import external data2:
mdione@diablo:~/src/projects/osm/data/osm$ time ../../osm-carto/scripts/get-external-data.py --config ../../osm-carto/external-data.yml --data . --database gis --port 5433 --username $USER --verbose 2>&1 | pefan.py -t '%Y-%m-%d %H:%M:%S' 2023-08-22 23:04:16: INFO:root:Checking table simplified_water_polygons 2023-08-22 23:04:19: INFO:root: Importing into database 2023-08-22 23:04:20: INFO:root: Import complete 2023-08-22 23:04:21: INFO:root:Checking table water_polygons 2023-08-22 23:06:16: INFO:root: Importing into database 2023-08-22 23:07:12: INFO:root: Import complete 2023-08-22 23:07:49: INFO:root:Checking table icesheet_polygons 2023-08-22 23:07:55: INFO:root: Importing into database 2023-08-22 23:07:59: INFO:root: Import complete 2023-08-22 23:08:01: INFO:root:Checking table icesheet_outlines 2023-08-22 23:08:06: INFO:root: Importing into database 2023-08-22 23:08:09: INFO:root: Import complete 2023-08-22 23:08:11: INFO:root:Checking table ne_110m_admin_0_boundary_lines_land 2023-08-22 23:08:12: INFO:root: Importing into database 2023-08-22 23:08:13: INFO:root: Import complete real 3m57,162s user 0m36,408s sys 0m15,387s
Notice how this time I changed pefan's -t option to have more consistent timestamps. The generated indexes are:
Name | Persistence | Access method | Size -------------------------------------+-------------+---------------+---------------- water_polygons | permanent | heap | 1_201_078_272 icesheet_outlines | permanent | heap | 83_951_616 icesheet_polygons | permanent | heap | 74_571_776 simplified_water_polygons | permanent | heap | 34_701_312 ne_110m_admin_0_boundary_lines_land | permanent | heap | 139_264 external_data | permanent | heap | 16_384 Name | Table | Access method | Size ---------------------------------------------+-------------------------------------+---------------+--------------- icesheet_outlines_way_idx | icesheet_outlines | gist | 3_325_952 icesheet_polygons_way_idx | icesheet_polygons | gist | 679_936 simplified_water_polygons_way_idx | simplified_water_polygons | gist | 630_784 water_polygons_way_idx | water_polygons | gist | 630_784 ne_110m_admin_0_boundary_lines_land_way_idx | ne_110m_admin_0_boundary_lines_land | gist | 24_576 external_data_pkey | external_data | btree | 16_384
Again, too small to care.
Let's summarize what we have.
We started with a 28GiB Europe export, which generated
298GiB of data and indexes, with a peak of 422GiB of usage during the clustering phase. This 'data and indexes' includes
an 83GiB flat nodes file, which I need to use because of the puny size of my rendering gig. This means a 10x explosion
on data size, but also a 15x peak usage (ballpark figures). As the peak happens in a part of the process that can't be
reordered, any other reordering in data import or index generation would provide no advantage. Maybe only if you used
--number-processes 1, and given how the clustering of tables are assigned to workers, I think it's already the right
order, except maybe swapping the last two, but they're also the smaller two; polygons was already the peak.
-
psqlusespg_catalog.pg_size_pretty()to print tables and indexes sizes, and it's hard coded on the query that it runs. Thanks to the people at#postgresql:libera.chatI found out that most of the slash commands (for instance, both\d+and\di+I used above) are implemented with SQL queries. You can find out which queries by using\set ECHO_HIDDEN 1and running them again. I sorted them by decreasing size, and I used Python's long int prettifying method :) I also removed uninteresting columns. ↩ -
I removed lines from this output that I think don't add new interesting info, and I split it in sections so it's easier to read and marks important milestones for the graphs later. ↩↩↩
-
I usually use a highlighter for these snippets, but alas, it's broken right now. I've been kicking down the road a migration out of
ikiwikito probablynikola, maybe it's time. ↩