For at least four months I've been trying to import the whole Europe in slim mode so it would allow updates.
The computer is a Lenovo quad-core with 8GiB of RAM and initially 500GiB of disk. Last time
I tried with the disk alone it took like 3 days to import just the data and
more than a week passed before I got tired and canceled the index creation. That's the
most expensive part of the import, and reading the data and writing the index
on a seeking device is slow.
So I bought a 256GB SSD and wanted to try again. I took 15GiB for the system and
the rest to share between my files and postgres, but having the data files on the HDD. At first I tried importing the
whole Europe, using 6GiB of cache; remember that my computer has 8GiB of RAM, I
though it would fit. It actually didn't and was killed by the OOM killer. I had logs that showed osm2pgsql
and the different postgres thread's memory usage, but somehow I lost them. If
I find them I'll post them. I lowered the cache to 4GiB but it was still too big
and the OOM killer was triggered again.
So I lowered the cache size to 2GiB, but then I was running out of disk space. I tried
using osm2pgsql --bbox to import only from Iceland to somewhere between Κύπρος
(Cyprus) and Κρήτη (Crete), so it includes Istambul and Sicilia,
but is was still too big. So I started wondering about the sizes of OSM data. I
ducked and googled around for them to no avail, but then
jburgess, the tile server sysadmin,
answered me the question on the IRC channel with
these numbers:
gis=# \d+
Schema | NAME | TYPE | OWNER | SIZE | Description
--------+--------------------+-------+-------+------------+-------------
public | geography_columns | VIEW | tile | 0 bytes |
public | geometry_columns | VIEW | tile | 0 bytes |
public | planet_osm_line | TABLE | tile | 44 GB |
public | planet_osm_nodes | TABLE | tile | 8192 bytes | *
public | planet_osm_point | TABLE | tile | 4426 MB |
public | planet_osm_polygon | TABLE | tile | 52 GB |
public | planet_osm_rels | TABLE | tile | 1546 MB | *
public | planet_osm_roads | TABLE | tile | 7035 MB |
public | planet_osm_ways | TABLE | tile | 59 GB | *
public | raster_columns | VIEW | tile | 0 bytes |
public | raster_overviews | VIEW | tile | 0 bytes |
public | spatial_ref_sys | TABLE | tile | 3216 kB |
gis=# \di+
Schema | NAME | TYPE | OWNER | TABLE | SIZE | Description
--------+--------------------------+-------+-------+--------------------+------------+-------------
public | ferry_idx | INDEX | tile | planet_osm_line | 824 kB |
public | leisure_polygon_idx | INDEX | tile | planet_osm_polygon | 1437 MB |
public | national_park_idx | INDEX | tile | planet_osm_polygon | 1608 kB |
public | planet_osm_line_index | INDEX | tile | planet_osm_line | 8937 MB |
public | planet_osm_line_pkey | INDEX | tile | planet_osm_line | 2534 MB |
public | planet_osm_nodes_pkey | INDEX | tile | planet_osm_nodes | 8192 bytes | *
public | planet_osm_point_index | INDEX | tile | planet_osm_point | 2565 MB |
public | planet_osm_point_pkey | INDEX | tile | planet_osm_point | 1232 MB |
public | planet_osm_polygon_index | INDEX | tile | planet_osm_polygon | 9295 MB |
public | planet_osm_polygon_pkey | INDEX | tile | planet_osm_polygon | 3473 MB |
public | planet_osm_rels_idx | INDEX | tile | planet_osm_rels | 208 kB | *
public | planet_osm_rels_parts | INDEX | tile | planet_osm_rels | 2837 MB | *
public | planet_osm_rels_pkey | INDEX | tile | planet_osm_rels | 75 MB | *
public | planet_osm_roads_index | INDEX | tile | planet_osm_roads | 1151 MB |
public | planet_osm_roads_pkey | INDEX | tile | planet_osm_roads | 301 MB |
public | planet_osm_ways_idx | INDEX | tile | planet_osm_ways | 2622 MB | *
public | planet_osm_ways_nodes | INDEX | tile | planet_osm_ways | 112 GB | *
public | planet_osm_ways_pkey | INDEX | tile | planet_osm_ways | 10 GB | *
public | spatial_ref_sys_pkey | INDEX | tile | spatial_ref_sys | 144 kB |
public | water_areas_idx | INDEX | tile | planet_osm_polygon | 564 MB |
public | water_lines_idx | INDEX | tile | planet_osm_line | 38 MB |
[*] These are the intermediate tables and their indexes
So, around 167GiB of data and around 158GiB of indexes, of which 60GiB and 127GiB
are intermediate, respectively. These intermediate tables and indexes are used
later during the updates. Clearly I couldn't import the whole planet, but surely
Europe should fit in ~210GiB?
planet.pbf weights
24063MiB and europe.pbf
scales at 12251MiB, so little bit more than 50%. It should fit, but somehow it
doesn't.
Having no more free space, I decided to both create a new tablespace in the HDD and
put the data tables there and the rest in the SSD, and to still reduce the north
limit to the British islands, cutting out Iceland and a good part of Scandinavia. osm2pgsql supports the former
with its --tablespace-main-data option. This is a summary of the successful import, with
human readable times between brackets added by me:
$ mdione@diablo:~/src/projects/osm/data/osm$ osm2pgsql --create --database gis --slim --cache 2048 --number-processes 4 --unlogged --tablespace-main-data hdd --bbox -11.9531,34.6694,29.8828,58.8819 europe-latest.osm.pbf
Node-cache: cache=2048MB, maxblocks=262145*8192, allocation method=11
Mid: pgsql, scale=100 cache=2048
Reading in file: europe-latest.osm.pbf
Processing: Node(990001k 263.4k/s) Way(139244k 11.37k/s) Relation(1749200 217.43/s) parse time: 24045s [~6h40]
Node stats: total(990001600), max(2700585940) in 3758s [~1h03]
Way stats: total(139244632), max(264372509) in 12242s [~3h24]
Relation stats: total(1749204), max(3552177) in 8045s [~2h14]
Going over pending ways...
100666720 ways are pending
Using 4 helper-processes
100666720 Pending ways took 21396s [~5h57] at a rate of 4704.93/s
node cache: stored: 197941325(19.99%), storage efficiency: 73.74% (dense blocks: 132007, sparse nodes: 66630145), hit rate: 20.02%
Stopped table: planet_osm_nodes in 1s
Stopped table: planet_osm_rels in 44s
All indexes on planet_osm_point created in 4006s [~1h07]
All indexes on planet_osm_roads created in 5894s [~1h38]
All indexes on planet_osm_line created in 11834s [~3h17]
All indexes on planet_osm_polygon created in 14862s [~4h07]
Stopped table: planet_osm_ways in 26122s [~7h15]
Osm2pgsql took 72172s overall [~20h24]
So, ~20h24 of import time, of which ~6h40 is fro the intermediate data, which went
into the SSD, almost 6h importing the real data, which went into the HDD, and
the rest indexing, which went again into the SSD. This is the final disk usage:
Schema | Name | Type | Owner | Size | Description
--------+--------------------+-------+--------+----------+-------------
public | geography_columns | view | mdione | 0 bytes |
public | geometry_columns | view | mdione | 0 bytes |
public | planet_osm_line | table | mdione | 11264 MB | **
public | planet_osm_nodes | table | mdione | 43008 MB |
public | planet_osm_point | table | mdione | 2181 MB | **
public | planet_osm_polygon | table | mdione | 23552 MB | **
public | planet_osm_rels | table | mdione | 871 MB |
public | planet_osm_roads | table | mdione | 2129 MB | **
public | planet_osm_ways | table | mdione | 43008 MB |
public | raster_columns | view | mdione | 0 bytes |
public | raster_overviews | view | mdione | 0 bytes |
public | spatial_ref_sys | table | mdione | 3 MB |
--------+--------------------+-------+--------+----------+--------------
total 126016 MB 39126 MB
Schema | Name | Type | Owner | Table | Size | Description
--------+-----------------------------+-------+--------+--------------------+----------+-------------
public | planet_osm_line_index | index | mdione | planet_osm_line | 4105 MB |
public | planet_osm_line_pkey | index | mdione | planet_osm_line | 748 MB |
public | planet_osm_nodes_pkey | index | mdione | planet_osm_nodes | 21504 MB |
public | planet_osm_point_index | index | mdione | planet_osm_point | 1506 MB |
public | planet_osm_point_pkey | index | mdione | planet_osm_point | 566 MB |
public | planet_osm_point_population | index | mdione | planet_osm_point | 566 MB |
public | planet_osm_polygon_index | index | mdione | planet_osm_polygon | 8074 MB |
public | planet_osm_polygon_pkey | index | mdione | planet_osm_polygon | 1953 MB |
public | planet_osm_rels_idx | index | mdione | planet_osm_rels | 16 kB | *
public | planet_osm_rels_parts | index | mdione | planet_osm_rels | 671 MB |
public | planet_osm_rels_pkey | index | mdione | planet_osm_rels | 37 MB |
public | planet_osm_roads_index | index | mdione | planet_osm_roads | 359 MB |
public | planet_osm_roads_pkey | index | mdione | planet_osm_roads | 77 MB |
public | planet_osm_ways_idx | index | mdione | planet_osm_ways | 2161 MB |
public | planet_osm_ways_nodes | index | mdione | planet_osm_ways | 53248 MB |
public | planet_osm_ways_pkey | index | mdione | planet_osm_ways | 6926 MB |
public | spatial_ref_sys_pkey | index | mdione | spatial_ref_sys | 144 kB | *
--------+-----------------------------+-------+--------+--------------------+-----------+
total 102501 MB
[*] Too small, not counted
[**] In tablespace 'hdd', which is in the HDD.
That's a total of 228517MiB for this partial Europe import, of which 171434MiB
are for the intermediate data. It's slightly more than
I have to spare in the SSD, so I should cut still more data off if I wanted to
import everything in the SSD. Then I tried to render with this, but it was
awfully slow.
Luckily, when jburgess answered with the sizes, he also suggested to use flat
nodes. This is an option for osm2pgsql which uses a special formatted file to
store the intermediate data instead of postgres tables. According to the manpage,
is faster for the import and the successive updates, and uses only about 16GiB of
disk space, which is around a 10% of what my import used for the intermediate
data but «[t]his mode is only recommended for full planet
imports as it doesn't work well with small extracts.». I tried anyways.
So I used that option to create the flat node cache on the SSD and put all the
data and indexes there too. Here's the summary:
mdione@diablo:~/src/projects/osm/data/osm$ osm2pgsql --create --drop --database gis --slim --flat-nodes /home/mdione/src/projects/osm/nodes.cache --cache 2048 --number-processes 4 --unlogged --bbox -11.9531,34.6694,29.8828,58.8819 europe-latest.osm.pbf
Node-cache: cache=2048MB, maxblocks=262145*8192, allocation method=11
Mid: pgsql, scale=100 cache=2048
Reading in file: europe-latest.osm.pbf
Processing: Node(990001k 914.1k/s) Way(139244k 17.64k/s) Relation(1749200 344.60/s) parse time: 14052s [~3h54]
Node stats: total(990001600), max(2700585940) in 1083s [~0h18]
Way stats: total(139244632), max(264372509) in 7893s [~2h11]
Relation stats: total(1749204), max(3552177) in 5076s [~1h24]
Going over pending ways...
100666720 ways are pending
Mid: loading persistent node cache from /home/mdione/src/projects/osm/nodes.cache
100666720 Pending ways took 29143s [~8h05] at a rate of 3454.23/s
node cache: stored: 197941325(19.99%), storage efficiency: 73.74% (dense blocks: 132007, sparse nodes: 66630145), hit rate: 18.98%
Stopped table: planet_osm_nodes in 0s
Stopped table: planet_osm_rels in 0s
All indexes on planet_osm_roads created in 1023s [~0h17]
All indexes on planet_osm_point created in 1974s [~0h33]
All indexes on planet_osm_line created in 4354s [~1h12]
All indexes on planet_osm_polygon created in 6777s [~1h52]
Stopped table: planet_osm_ways in 2s
Osm2pgsql took 50092s overall [~13h54]
So we went from 20h24 down to 13h54 for the whole operation, from 6h40 down to
3h54 for the intermediate data, from 5h57 up to 8h05 for the real data, and a lot
less time from the indexing, like a third for each real data table and from 7h15
all the way down to 0 for the intermediate data. So even if the
real data processing time went up more than 2h more, the whole import time is only
~68%, uses less space, and it fits in my SSD, with a lot of space to spare. For reference, the file
nodes.cache uses only 20608MiB of disk space, which is ~12% of the space used
by the intermediate postgres tables.
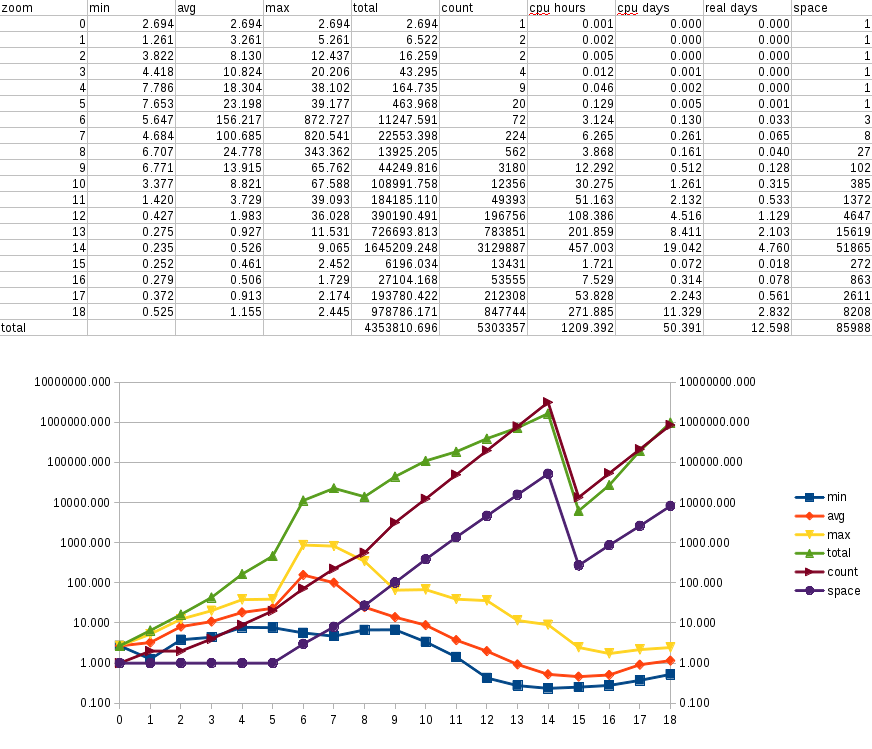
So, now, what about rendering time? This question is not easy to answer. I set
up a very rough benchmark, which consists in rendering only one tile for each
zoom level in a small town chosen without any particular criteria.
I used Tilemill to export my modified version of openstreetmap-carto to a
Mapnik XML file, and used a modified generate_tiles.py to measure the rendering
times. This is the resulting logarithmic graph:
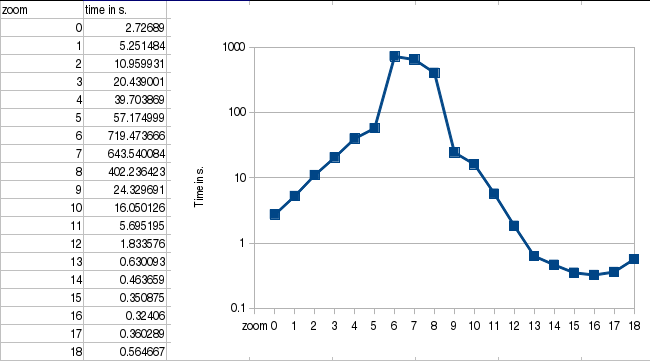
Notice how the render time increases exponentially (it looks linear in the graph)
between zoom levels 0 and 5, and then the big peaks (up to 720s!) for zoom levels
6 to 8. This is definitely worse than the render times I used to have when I
imported several countries, but that data never got to the size of this import.
Of course, next weekend I'll fire a full render for the imported region between
zoom levels 0 to 14, and then I'll have better numbers to share.
Meanwhile, when I tried to update the data, it failed:
mdione@diablo:~/src/projects/osm/data/osm$ osm2pgsql --append --database gis --slim --flat-nodes /home/mdione/src/projects/osm/nodes.cache --cache 2048 --number-processes 4 362.osc.gz
osm2pgsql SVN version 0.82.0 (64bit id space)
Node-cache: cache=2048MB, maxblocks=262145*8192, allocation method=11
Mid: loading persistent node cache from /home/mdione/src/projects/osm/nodes.cache
Maximum node in persistent node cache: 2701131775
Mid: pgsql, scale=100 cache=2048
Setting up table: planet_osm_nodes
PREPARE insert_node (int8, int4, int4, text[]) AS INSERT INTO planet_osm_nodes VALUES ($1,$2,$3,$4);
PREPARE get_node (int8) AS SELECT lat,lon,tags FROM planet_osm_nodes WHERE id = $1 LIMIT 1;
PREPARE delete_node (int8) AS DELETE FROM planet_osm_nodes WHERE id = $1;
failed: ERROR: relation "planet_osm_nodes" does not exist
LINE 1: ...rt_node (int8, int4, int4, text[]) AS INSERT INTO planet_osm...
^
Error occurred, cleaning up
Somehow it's trying to use a table that was not created because the intermediate
data is in the flat nodes file. I will have to investigate this; I'll try to do
it this week.