First: one thing I didn't do in previous post was to show the final tables and
sizes. Here it is:
Schema | Name | Type | Owner | Size | Description
--------+--------------------+-------+--------+---------+-------------
public | geography_columns | view | mdione | 0 bytes |
public | geometry_columns | view | mdione | 0 bytes |
public | planet_osm_line | table | mdione | 11 GB |
public | planet_osm_point | table | mdione | 2181 MB |
public | planet_osm_polygon | table | mdione | 23 GB |
public | planet_osm_roads | table | mdione | 2129 MB |
public | raster_columns | view | mdione | 0 bytes |
public | raster_overviews | view | mdione | 0 bytes |
public | spatial_ref_sys | table | mdione | 3216 kB |
Schema | Name | Type | Owner | Table | Size | Description
--------+-----------------------------+-------+--------+--------------------+---------+-------------
public | planet_osm_line_index | index | mdione | planet_osm_line | 4027 MB |
public | planet_osm_point_index | index | mdione | planet_osm_point | 1491 MB |
public | planet_osm_point_population | index | mdione | planet_osm_point | 566 MB |
public | planet_osm_polygon_index | index | mdione | planet_osm_polygon | 8202 MB |
public | planet_osm_roads_index | index | mdione | planet_osm_roads | 355 MB |
public | spatial_ref_sys_pkey | index | mdione | spatial_ref_sys | 144 kB |
The first thing to notice is that none of the intermediate tables are created nor
their indexes, but also all the _pkey indexes are missing.
What I did in my previous post was to say that I couldn't update because the
intermediate tables were missing. That was actually my fault. I didn't read carefully
osm2psql's manpage, so it happens that the --drop option is not for dropping
the tables before importing but for dropping the intermediate after import.
This means I had to reimport everything, and this time I made sure that I had the
memory consumption log. But first, the final sizes:
Schema | Name | Type | Owner | Size | Description
--------+--------------------+----------+--------+------------+-------------
public | contours | table | mdione | 21 GB |
public | contours_gid_seq | sequence | mdione | 8192 bytes |
public | geography_columns | view | mdione | 0 bytes |
public | geometry_columns | view | mdione | 0 bytes |
public | planet_osm_line | table | mdione | 11 GB |
public | planet_osm_nodes | table | mdione | 16 kB |
public | planet_osm_point | table | mdione | 2181 MB |
public | planet_osm_polygon | table | mdione | 23 GB |
public | planet_osm_rels | table | mdione | 871 MB |
public | planet_osm_roads | table | mdione | 2129 MB |
public | planet_osm_ways | table | mdione | 42 GB |
public | raster_columns | view | mdione | 0 bytes |
public | raster_overviews | view | mdione | 0 bytes |
public | spatial_ref_sys | table | mdione | 3216 kB |
Schema | Name | Type | Owner | Table | Size | Description
--------+--------------------------+-------+--------+--------------------+---------+-------------
public | contours_height | index | mdione | contours | 268 MB |
public | contours_pkey | index | mdione | contours | 268 MB |
public | contours_way_gist | index | mdione | contours | 1144 MB |
public | planet_osm_line_index | index | mdione | planet_osm_line | 4022 MB |
public | planet_osm_line_pkey | index | mdione | planet_osm_line | 748 MB |
public | planet_osm_nodes_pkey | index | mdione | planet_osm_nodes | 16 kB |
public | planet_osm_point_index | index | mdione | planet_osm_point | 1494 MB |
public | planet_osm_point_pkey | index | mdione | planet_osm_point | 566 MB |
public | planet_osm_polygon_index | index | mdione | planet_osm_polygon | 8207 MB |
public | planet_osm_polygon_pkey | index | mdione | planet_osm_polygon | 1953 MB |
public | planet_osm_rels_idx | index | mdione | planet_osm_rels | 16 kB |
public | planet_osm_rels_parts | index | mdione | planet_osm_rels | 671 MB |
public | planet_osm_rels_pkey | index | mdione | planet_osm_rels | 37 MB |
public | planet_osm_roads_index | index | mdione | planet_osm_roads | 358 MB |
public | planet_osm_roads_pkey | index | mdione | planet_osm_roads | 77 MB |
public | planet_osm_ways_idx | index | mdione | planet_osm_ways | 2161 MB |
public | planet_osm_ways_nodes | index | mdione | planet_osm_ways | 52 GB |
public | planet_osm_ways_pkey | index | mdione | planet_osm_ways | 6922 MB |
public | spatial_ref_sys_pkey | index | mdione | spatial_ref_sys | 144 kB |
This time you'll probably notice a difference: there's this new contours table
with a couple of indexes. This table contains data that I'll be using for drawing
hypsometric lines (also know as contour lines) in my map. This 21GiB table contains
all the data from 0 to 4000+m in 50m increments for the whole Europe and some parts of Africa and Asia, except for
that above 60°, which means that Iceland, most of Scandinavia and the North of
Russia is out. At that size, I think it's a bargain.
As with jburgess' data, we have the intermediate data, and quite a lot.
Besides the 21GiB extra for contours, we have notably 42+52+2+7GiB for ways.
In practice this means that, besides of some of my files, OSM+contour data uses
almost all the 220GiB of SSD space, so I'll just move all my stuff out of the SSD
:( Another alternative would be to just reimport the whole data from time to time
(once a month or each time I update my rendering rules, which I plan to do based
on openstreetmap-carto's releases, but not on each one of them).
During the import I logged the memory usage of the 10 more memory hungry processes
in the machine with this command:
( while true; do date -R; ps ax -o rss,vsize,pid,cmd | sort -rn | head; sleep 60; done ) | tee -a mem.log
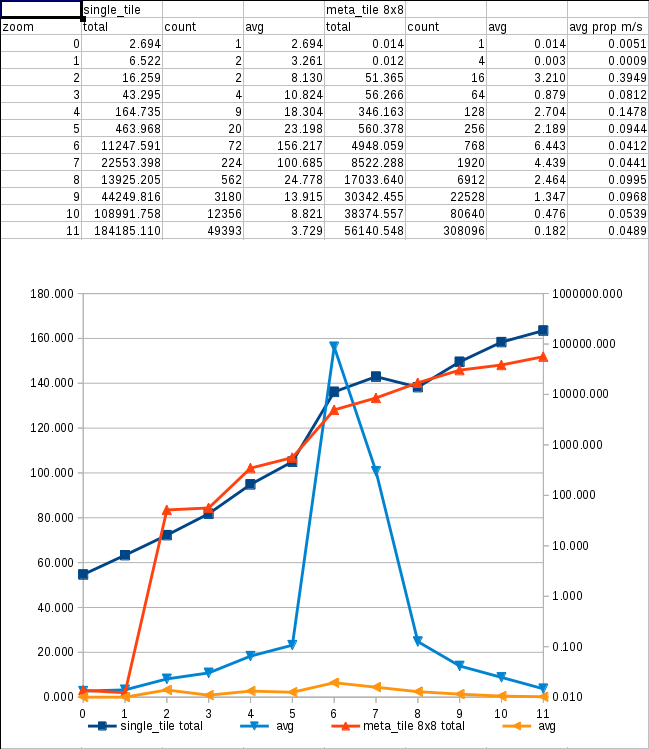
Then I massaged that file with a little bit of Python and obtained a CVS file
which I graphed with LibreOffice. I tried several formats and styles, but to
make things readable I only graphed the sum of all the postgres processes and
osm2psql. This is the final graph:
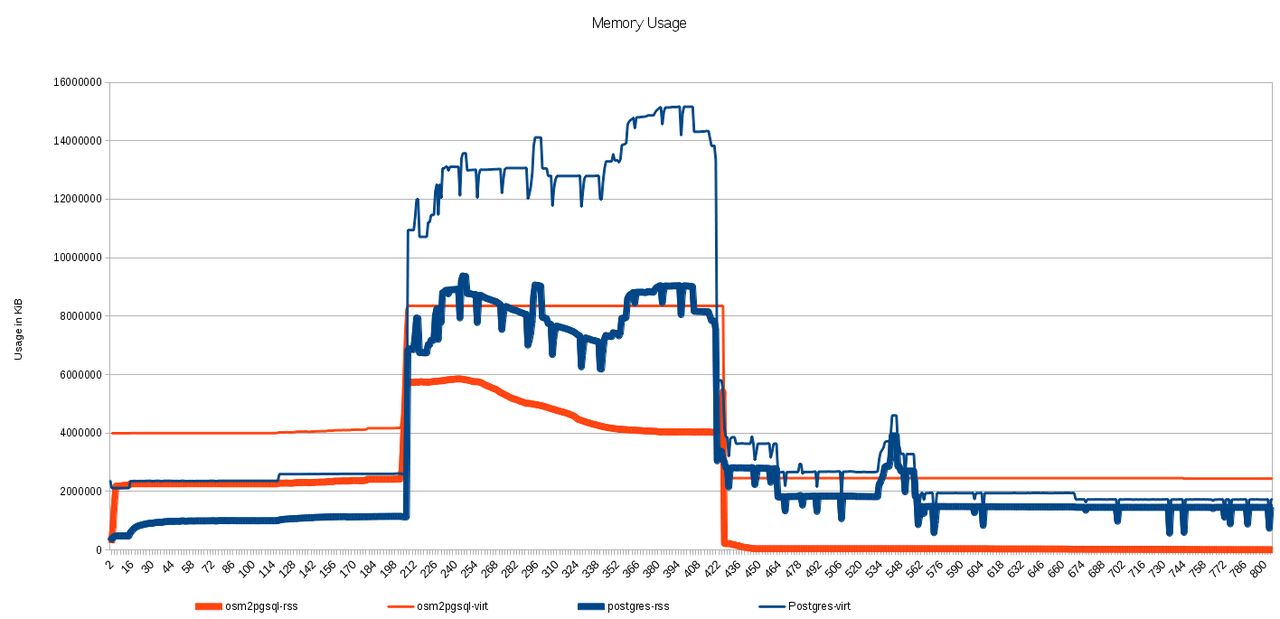
Here you can see 4 lines, 2 for the sum of postgres and two for osm2psql.
The thick lines graph the RSS for them, which is the resident, real RAM usage
of that process. The correspondent thin line shows the VIRT size, which is the
amount of memory malloc()'ed by the processes. As with any memory analysis
under Linux, we have the problem that all the processes report also the memory
used by the libraries used by them, and if there are common libraries among them,
they will be reported several times. Still, for the amounts of memory we're
talking about here, we can say it's negligible against the memory used by the data.
In the graph we can clearly see the three phases of the import: first filling
up the intermediate tables, then the real data tables themselves, then the
indexing. The weird curve we can see in the middle phase for osm2psql can be
due to unused memory being swapped out. Unluckily I didn't log the memory/swap usage
to support this theory, so I'll have it in account for the next run, if there is
one. In any case, the peak at the end of the second phase seems to also support
the idea.
One thing that surprises me is the real amount of memory used by osm2psql. I
told him to use 2GiB for cache, but at its peak, it uses 3 times that amount,
and all the time it has another 2GiB requested to the kernel. The middle phase
is also hard on postgres, but it doesn't take that much during indexing; luckily,
at that moment osm2psql has released everything, so most of the RAM is used as
kernel cache.
13 paragraphs later, I finally write about the reason of this post, updating the
database with daily diffs. As I already mentioned, the data as imported almost took
all the space available, so I was very sensitive about the amount of space used
by them. But first to the sizes and times.
The file 362.osc.gz, provided by Geofabrik as the diff for Europe for Mar05
weights almost 25MiB, but it's compressed XML inside. Luckily osm2psql can read
them directly. Here's the summary of the update:
$ osm2pgsql --append --database gis --slim --flat-nodes /home/mdione/src/projects/osm/nodes.cache --cache 2048 --number-processes 4 --unlogged --bbox -11.9531,34.6694,29.8828,58.8819 362.osc.gz
Node-cache: cache=2048MB, maxblocks=262145*8192, allocation method=11
Mid: loading persistent node cache from /home/mdione/src/projects/osm/nodes.cache
Maximum node in persistent node cache: 2701131775
Mid: pgsql, scale=100 cache=2048
Reading in file: 362.osc.gz
Processing: Node(882k 3.7k/s) Way(156k 0.65k/s) Relation(5252 25.50/s) parse time: 688s [11m28]
Node stats: total(882823), max(2701909278) in 240s [4m00]
Way stats: total(156832), max(264525413) in 242s [4m02]
Relation stats: total(5252), max(3554649) in 206s [3m26]
Going over pending ways...
Maximum node in persistent node cache: 2701910015
122396 ways are pending
Using 4 helper-processes
Process 3 finished processing 30599 ways in 305 sec [5m05]
Process 2 finished processing 30599 ways in 305 sec
Process 1 finished processing 30599 ways in 305 sec
Process 0 finished processing 30599 ways in 305 sec
122396 Pending ways took 307s at a rate of 398.68/s [5m07]
Going over pending relations...
Maximum node in persistent node cache: 2701910015
9432 relations are pending
Using 4 helper-processes
Process 3 finished processing 2358 relations in 795 sec [13m15]
Process 0 finished processing 2358 relations in 795 sec
Process 1 finished processing 2358 relations in 795 sec
Process 2 finished processing 2358 relations in 810 sec [13m30]
9432 Pending relations took 810s at a rate of 11.64/s
node cache: stored: 675450(100.00%), storage efficiency: 61.42% (dense blocks: 494, sparse nodes: 296964), hit rate: 5.12%
Osm2pgsql took 1805s overall [30m05]
This time is in the order of minutes instead of hours, but still, ~30m for only
25MiB seems a little bit too much. If I process the diff files daily, it would
take ~15h a month to do it, but spread in ~30m stretches on each day. Also, that
particular file was one of the smallest I have (between Mar03 and Mar17); most
of the rest are above 30MiB, up to 38MiB for Mar15 and 17 each. Given the space
problems that this causes, I might as well import before each rerender. Another
thing to note is that the cache is quite useless, falling from ~20% to ~5% hit
rate. I could try with lower caches too. The processing speeds are awfully smaller
than at import time, but the small amount of data is the prevailing here.
Sizes:
Schema | Name | Type | Owner | Size | Description
--------+--------------------+----------+--------+------------+-------------
public | contours | table | mdione | 21 GB |
public | contours_gid_seq | sequence | mdione | 8192 bytes |
public | geography_columns | view | mdione | 0 bytes |
public | geometry_columns | view | mdione | 0 bytes |
public | planet_osm_line | table | mdione | 11 GB |
public | planet_osm_nodes | table | mdione | 16 kB |
public | planet_osm_point | table | mdione | 2184 MB |
public | planet_osm_polygon | table | mdione | 23 GB |
public | planet_osm_rels | table | mdione | 892 MB |
public | planet_osm_roads | table | mdione | 2174 MB |
public | planet_osm_ways | table | mdione | 42 GB |
public | raster_columns | view | mdione | 0 bytes |
public | raster_overviews | view | mdione | 0 bytes |
public | spatial_ref_sys | table | mdione | 3224 kB |
Schema | Name | Type | Owner | Table | Size | Description
--------+--------------------------+-------+--------+--------------------+---------+-------------
public | contours_height | index | mdione | contours | 268 MB |
public | contours_pkey | index | mdione | contours | 268 MB |
public | contours_way_gist | index | mdione | contours | 1144 MB |
public | planet_osm_line_index | index | mdione | planet_osm_line | 4024 MB |
public | planet_osm_line_pkey | index | mdione | planet_osm_line | 756 MB |
public | planet_osm_nodes_pkey | index | mdione | planet_osm_nodes | 16 kB |
public | planet_osm_point_index | index | mdione | planet_osm_point | 1494 MB |
public | planet_osm_point_pkey | index | mdione | planet_osm_point | 566 MB |
public | planet_osm_polygon_index | index | mdione | planet_osm_polygon | 8210 MB |
public | planet_osm_polygon_pkey | index | mdione | planet_osm_polygon | 1955 MB |
public | planet_osm_rels_idx | index | mdione | planet_osm_rels | 352 kB |
public | planet_osm_rels_parts | index | mdione | planet_osm_rels | 676 MB |
public | planet_osm_rels_pkey | index | mdione | planet_osm_rels | 38 MB |
public | planet_osm_roads_index | index | mdione | planet_osm_roads | 358 MB |
public | planet_osm_roads_pkey | index | mdione | planet_osm_roads | 78 MB |
public | planet_osm_ways_idx | index | mdione | planet_osm_ways | 2165 MB |
public | planet_osm_ways_nodes | index | mdione | planet_osm_ways | 52 GB |
public | planet_osm_ways_pkey | index | mdione | planet_osm_ways | 6926 MB |
public | spatial_ref_sys_pkey | index | mdione | spatial_ref_sys | 104 kB |
3MiB more of points, 21+5+1MiB more of rels, 45+1MiB more of roads, 0+2+8MiB
more of lines, 0+3MiB for polygons, 0+4+4MiB for ways. In total, some 97MiB more.
I tried a VACUUM at the end, but no space was gained, and I don't have enough
space for VACUUM FULL. As VACUUM does not defragment, a second and third updates
should make use of the internal fragmentation. Let's see.
363.osc.gz is the smalest file I have, at ~22MiB. The times are internally
different, but overall looks proportional:
$ osm2pgsql --append --database gis --slim --flat-nodes /home/mdione/src/projects/osm/nodes.cache --cache 2048 --number-processes 4 --bbox -11.9531,34.6694,29.8828,58.8819 363.osc.gz
Maximum node in persistent node cache: 2701910015
Reading in file: 363.osc.gz
Processing: Node(750k 3.3k/s) Way(128k 0.44k/s) Relation(4264 15.73/s) parse time: 792s
Node stats: total(750191), max(2703147051) in 230s
Way stats: total(128987), max(264655143) in 291s
Relation stats: total(4264), max(3556985) in 271s
Going over pending ways...
Maximum node in persistent node cache: 2703148031
94490 ways are pending
Using 4 helper-processes
Process 0 finished processing 23623 ways in 238 sec
Process 2 finished processing 23622 ways in 238 sec
Process 1 finished processing 23623 ways in 238 sec
Process 3 finished processing 23622 ways in 239 sec
94490 Pending ways took 241s at a rate of 392.07/s
Going over pending relations...
Maximum node in persistent node cache: 2703148031
8413 relations are pending
Using 4 helper-processes
Process 1 finished processing 2103 relations in 443 sec
Process 3 finished processing 2103 relations in 445 sec
Process 0 finished processing 2104 relations in 450 sec
Process 2 finished processing 2103 relations in 452 sec
8413 Pending relations took 453s at a rate of 18.57/s
node cache: stored: 576093(100.00%), storage efficiency: 60.50% (dense blocks: 437, sparse nodes: 252366), hit rate: 5.07%
Osm2pgsql took 1488s overall
The table sizes keep growing, as expected: OSM data does nothing but grow; my
free space does nothing but shrink, currently at mere 249MiB. Given
that the intermediate tables are dropped at the end of the second import phase,
it only makes sense to do full imports from time to time, before updating the
rendering rules. Munitely is not for me.