Measure your optimnizations
One of the parts of having my own map style with hypsometric contour lines is that I
have to generate those contour lines. There's a tool in GDAL, particularly the one that
actually does everything based on DEM files, called gdaldem that
can generate shapefiles with contour lines that mapnik can read.
But since my source files are 1x1° files, I will have to generate one layer for
each shapefile and that doesn't scale very well, especially
at planet size.
So what I do is I convert those shapefiles to SQL files and then I inject
them into my database one by one, and then I can use mapnik's own support for filtering
by bbox when it's rendering, so that should be faster4.
I put the SQL files in my file system, and then I import them by hand as I need them, and I'm running out of space again. A few years ago I had a 1TB disk, and that was enough, and now I am at the 2TB disk, and it's getting small. I have the impression that the new DEMs I am using are bigger, even if I streamlined every layer so it uses as less space as possible.
One of the things I'm doing
is converting my processing script into a Makefile, so I can remove intermediary files. My process goes
from the original DEM files, that are in LatLon, I project them to WebMerkator.
This file becomes the source for the terrain files, which gives the hypsometric
tints, and I generate the contours from there, and then I do a
compensation for slope shade and hill shade.
Notice that I get
two intermediary files that I can easily remove, which are first, the reprojected file, because
once I have the terrain and contour files, I can remove it, I don't care anymore;
and also the compensated file, I don't need it anymore once I have the shade files.
The Makefile is covering that part,
once the files are generated, the intermediary files are gone.
Going back to the SQL files, I don't inject SQL data directly into my database, because I don't have space for
that. So, I just generate this SQL file and I compress it, so it's not using so much space,
because SQL is really a lot of text. I've been using xz as the compressor,
and I have been blindly using its highest compression level, CL 9.
What do I mean with
blindly? I noticed it actually takes a lot of time. I just measured it with one tile,
and it took 451 seconds. That's 7.5 minutes per degree tile,
which is a lot. So I asked myself, what's the compression ratio to time
spent ratio?
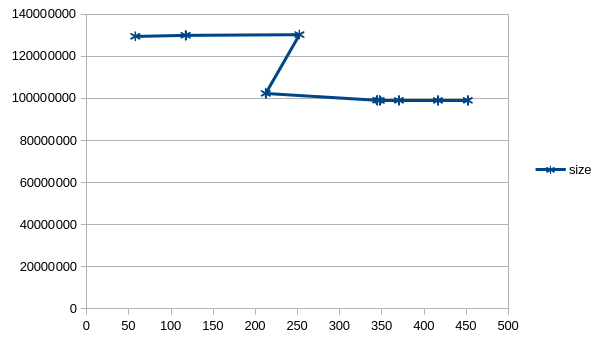
I took a single file and I compressed it with all the compression levels between 1 and 9, and I took the time and the space in the final file. I made a scatter graph, and it looks like this pretty weird Z figure2:
Here's the raw data1:
| level | time_in_seconds | readable_time | size_in_bytes | comp_ratio |
|---|---|---|---|---|
| 1 | 57.84 | 57s | 129_486_376 | 29.21% |
| 2 | 117.40 | 1m57s | 129_993_440 | 29.33% |
| 3 | 252.28 | 4m12s | 130_306_780 | 29.40% |
| 4 | 212.26 | 3m32s | 102_359_596 | 23.09% |
| 5 | 347.51 | 5m47s | 98_992_464 | 22.33% |
| 6 | 344.58 | 5m44s | 99_114_560 | 22.36% |
| 7 | 370.20 | 6m10s | 99_043_096 | 22.34% |
| 8 | 416.48 | 6m56s | 99_005_352 | 22.33% |
| 9 | 451.85 | 7m31s | 99_055_552 | 22.35% |
I'm not going to explain the graph or table, except to point to the two obvious parts: the jump from CL 3 to 4, where it's not only the first and only noticeable space gain, it also takes less time; and the fact that compressions levels 1-3 and 4-9 have almost no change in space gained. So I either use CL 1 or 4. I'll go for 1, until I run out of space again.
All this to say: whenever you make an optimization, measure all the dimensions, time, space, memory consumption, and maybe you have other constraints like, I don't know, heat produced, stuff like that. Measure and compare.
-
Sorry for the ugly table style. I still don't know how to style it better. ↩
-
Sorry for the horrible scales. Either I don't know it enough, or LibreOffice is quite limited on how to format the axises3. ↩
-
No, I won't bother to see how the plural is made, this is taking me long enough already :-P ↩
-
This claim has not been proven and it's not in the scope of this post. ↩